CS385 - Computer Architecture
Spring-2024
Classes: TR 9:25am - 10:40am, Maria Sanford Hall 204
Instructor: Dr. Zdravko Markov, MS 30307, (860)-832-2711,
http://www.cs.ccsu.edu/~markov/, e-mail: markovz at ccsu dot edu
Office hours: MW 4:30pm-6:00 pm, TR 10:45am-12:00pm, in person.
Book an appointment here.
Catalog description: The architecture of the
computer is explored by studying its various levels: physical level,
operating-system level, conventional machine level and higher levels. An
introduction to microprogramming and computer networking is provided.
Course Prerequisites: CS 354
Prerequisites by topic
- Basic skills in software design and programming
- Assembly language programming and basics of computer organization
- Digital systems design
- Boolean algebra and discrete mathematics
Course description
The course provides a comprehensive coverage
of computer architecture. It discusses the main components of the computer and
the basic principles of its operation. It demonstrates the relationship between
the software and the hardware and focuses on the foundational concepts that are
the basis for current computer design. The course is based on the MIPS
processor, a simple clean RISC processor whose architecture is easy to learn and
understand. The major topics covered in the course are the following:
- MIPS instruction set
- Computer arithmetic and ALU design
- Datapath and control
- Using Hardware Description Language to design and simulate the CPU
- Pipelining
- Memory hierarchy, caches and virtual memory
- Interfacing CPU and peripherals, buses
- Multiprocessors, networks of multiprocessors, parallel programming
- Performance issues
Course Learning Outcomes (CLO)
- Understand the fundamentals of different instruction set architectures and
their relationship to the CPU design.
- Understand the principles and the implementation of computer
arithmetic.
- Understand the operation of modern CPUs including pipelining, memory
systems and busses.
- Understand the principles of operation of multiprocessor systems and
parallel programming.
- Design and emulate a single cycle or pipelined CPU by given specifications
using Hardware Description Language (HDL).
- Work in teams to design and implement CPUs.
- Write reports and make presentations of computer architecture
projects.
The CS 385 Course Learning Outcomes support the following Student
Outcomes (SO):
- SO-2: Design, implement, and evaluate a computing-based solution to meet a given set of computing requirements in the context of the program s discipline
(supported by CLO's 5, 6, 7).
- SO-6: Apply computer science theory and software development fundamentals to produce computing-based solutions
(supported by CLO's 1, 2, 3, 4).
Required textbook
Required software
- Icarus
Verilog: HDL compiler and simulator available for download from http://bleyer.org/icarus/ and online at https://www.jdoodle.com/execute-verilog-online.
- SPIM
simulator: A software simulator for running MIPS32 programs available for Windows and other platforms.
Semester project: There will be a semester project to build a simplified MIPS machine.
The projects will be done in teams of 2-3 people and will require four progress reports and a presentation. The machine must be implemented in HDL Verilog,
tested with a sample MIPS program and properly documented. The progress reports must be submitted via Blackboard at https://ccsu.blackboard.com/.
Class Participation: Active participation in
class is expected of all students. Regular attendance is also expected. If you
must miss a class, try to inform the instructor of this in advance. In case of
missed classes and work due to plausible reasons (such as illness or accidents)
limitted assistance will be offered. Unexcused absences will result in the
student being totally responsible for the make-up process.
Course Expectations for Out-of-Class Work:
To succeed in this 3-credit class, it is expected that you commit a total of 12 hours
per week to master the course material. This includes 2.5 hours of lecture time and
an additional 9.5 hours dedicated to independent study and coursework.
This time commitment aligns with the expectations set by the Computer Science
department for major courses and adheres to university policies.
Recognizing that dedicating this amount of time outside the classroom is a significant
commitment, it is nevertheless necessary for success. Please plan your course load
accordingly.
Honesty policy: The CCSU honor code for
Academic Integrity is in effect in this class. It is expected that all students
will conduct themselves in an honest manner and NEVER claim work which is not
their own. Violating this policy will result in a substantial grade penalty, and
may lead to expulsion from the University. You may find it online at http://web.ccsu.edu/academicintegrity/. Please read it
carefully.
Grading: Grading will be based on one
programming assignment (10%), a midterm test (20%), a final exam (25%) and a
semester project (45%, including progress reports, the final documentation, and
the presentation). The letter grades will be calculated according to the
following table:
| A |
A- |
B+ |
B |
B- |
C+ |
C |
C- |
D+ |
D |
D- |
F |
| 95-100 |
90-94 |
87-89 |
84-86 |
80-83 |
77-79 |
74-76 |
70-73 |
67-69 |
64-66 |
60-63 |
0-59 |
Unexcused late submission policy: Submissions
made more than two days after the due date will be graded one letter
grade down. Submissions made more than a week late will receive
two letter grades down. No submissions will be accepted more than two
weeks after the due date.
Students with disabilities: Students who
believe they need course accommodations based on the impact of a disability,
medical condition, or emergency should contact me privately to discuss
their specific needs. I will need a copy of the accommodation letter from
Accessibility Services in order to arrange class accommodations. Contact
Office of Accessibility Services, Willard-DiLoreto Hall, Suite W201 if you are not already
registered with them. Office of Accessibility Services maintains the confidential
documentation of your disability and assists you in coordinating reasonable
accommodations with your faculty.
Tentative schedule of classes and assignments
Note:
Dates for classes, assignments and tests may change (see also University Calendar). The lecture notes may also be updated.
Check the schedule and the class pages regularly for updates!
- Jan 18: Introduction: Computer Architecture = Instruction Set Architecture + Machine
Organization
- Jan 23: Review of HDL (Figure 6.5,
behavioral_serial_adder.vl,
Digital Design Review Assignment)
- Jan 25: MIPS Instructions: arithmetic, registers, memory, fecth&execute cycle
- Jan 30: MIPS Instructions: control and addressing modes
- Feb 1: Computer arithmetic and ALU design:
representing numbers, arithmetic and logic operations
- Feb 1: Submit Digital
Design Review Assignment (optional, for extra credit)
- Feb 6: ALU design: multiplication, representing floating point numbers
- Feb 8: ALU design: full adder, slt operation, HDL design
- Feb 13: Class canceled due to snow storm
- Feb 13: Assignment 1 due (10 pts.)
- Feb 15: The Processor: Building a datapath
- Feb 15: Semester Project is posted. Form teams for the Semester Project. Email me the team members.
- Feb 20: The Processor: Control (single cycle approach)
- Feb 22: Using Hardware Description Language to Design and Simulate the MIPS
processor. Review of Semester Project Report #1.
- Feb 27: Introduction to pipelining
- Feb 29: Progress Report #1 due (10 pts.): A simpilfied
single-cycle datapath capable of executing immediate and
R-type instructions. See Semester
Project for details.
- Feb 29: Solving pipeline hazards
- March 5: Implementing pipeline datapath and control
- March 7: Implementing data and branch hazards control
- March 19: Review of Datapath, Control and Pipelining.
Review of Progress Report 2.
- March 21: Review for Midterm Test
- March 26: Midterm Test (20 pts.)
- March 26: Progress Report #2 due (10 pts.): Complete
single-cycle datapath. See Semester Project for details.
- March 28: Implementing a 3-stage pipeline in HDL (mips-pipe3.png,
mips-pipe3.vl).
Progress Report #3 posted.
- April 2: Memory hierarchy,
The Basics of caches
- April 4: Improving cache performance
- April 9: Virtual Memory
- April 11: Virtual Memory optimization
- April 11: Progress Report #3 due (10 pts.): 3-stage pipelined datapath for immediate and R-type instructions. See Semester Project for details.
- April 16: Review of Final Report (complete 5-stage pipeline,
mips-pipe.vl)
- April 18: A general framework of memory hierarchies
- April 23: Multiprocessors
- April 25: Networks of muiltiprocessors
- April 30: Final Project Report and Presentation Slides due (10 pts.)
- April 30: Semester Project Presentations, Review for Final Exam
- May 2: Semester Project Presentations, Review for Final Exam
- May 7, 8:00 AM - 10:00 AM Final Exam (25 pts.)
CS385 Computer Architecture, Lecture
1
Reading: Patterson & Hennessy - Chapter 1
Topics: Introduction, Computer
Architecture = Instruction Set Architecture + Machine Organization, Performance.
Lecture slides
Lecture Notes
- Levels of Abstraction
- Computer Architecture = Instruction Set Architecture + Machine
Organization
- Instruction Set The Software Hardware Interface
- Levels of Computer Architecture in More Depth
- Software:
- Application
- Operating System
- Firmware
- Instruction Set Architecture:
- Organization of Programmable Storage
- Data type and Structures: encodings and machine representation
- Instruction set
- Instruction Formats
- Addressing Modes and Accessing Data and Instructions
- Exception Handling
- Hardware:
- Instruction Set Processing
- I/O System
- Digital Design
- Circuit Design
- Layout
- Basic Components of a Computer
- Processor: Datapath and Control
- Memory
- I/O
- Computer Organization
- Capabilities and Performance of the Basic Functional Units
- The Way These Units are Interconnected
- Information Flow between components
- Information Flow Control
- Performance
- Measuring and improving computer performance
- Program execution time
- CPU time
- Power
- Evaluating computer systems
- Relative performance
- Workload
- Benchmarks
- Amdahl's Law
CS385 Computer Architecture, Lecture
2
Reading: Patterson & Hennessy - Sections 2.1 - 2.3, 2.5, 2.6,
2.10, 2.13, A.9, A.10, Introduction to MIPS Assembly Language.
Topics: MIPS instructions, arithmetic,
registers, memory, fecth& execute cycle, SPIM simulator
Lecture slides
Lecture Notes
- Design goal: maximize performance and minimize cost. Primitive (low level)
and very restrictive instructions (fixed number and type of operands).
- Design principles:
- Simplicity favors regularity (uniform instruction format)
- Smaller is faster (only 32 registers)
- Good design demands a compromise (I-type instructions)
- MIPS arithmetic: 3 operands, fixed order, registers only.
- Using only registers: R-type instructions.
- Registers: 32-bits long, conventions.
- Memory organization: words and byte addressing.
- Data transfer (load and store) instructions. Example: accessing array
elements.
- Translating C code into MIPS instructions the swap example.
- Machine Language: instruction format, I-type (Immediate) format for data
transfer
- Stored program concept (Von Neumann Architecture): programs in memory, fetch & execute cycle
Exercises: Load this program in the SPIM simulator and analyze the format of
the insturctions. Run the program with different values of X and Y and trace the
execution in step mode.
CS385 Computer Architecture, Lecture
3
Reading: Patterson & Hennessy - Sections 2.7, 2.10, A.9, A.10
Topics: MIPS Instructions: control and addressing modes
Lecture slides
Book slides
Lecture Notes
- Implementing the C code for if in MIPS: conditional branch.
- Implementing the C code for if else in MIPS: unconditional branch
- Simple for loop
- Check for less-than: building a pseudoinstuction for branch if
less-than.
- Addressing in branch instructions: PC-relative and pseudodirect.
- Constants: use of immediate addressing (constants as operands addi,
slti, andi, ori)).
- 32-bit constants manipulate upper 2 bytes separately (load upper
immediate)
- Summary of MIPS addressing: register (add), immediate (addi), base or
displacement (lw), PC-relative (bne), pseudodirect (j)
Exercises: Load this program in the SPIM simulator and run it with and without pseudo instructions.
See how the compiler translates pseudo instructions into machine instructions.
CS385 Computer Architecture, Lecture
4
Reading: Patterson & Hennessy - Sections 2.4, 3.2, B.5.
Topics: Computer arithmetic and ALU design: representing numbers,
arithmetic and logic operations
Lecture slides
Lecture Notes
- Representing numbers: sign bit, one's complement, two's complement.
- Arithmetic: addition, subtraction, detecting overflow.
- Logical operations: shift, and, or.
- Basic ALU building components: and-gate, or-gate, inverter,
multiplexor.
- ALU for logical operations.
- ALU for add, and, or.
- Supporting subtraction
Tutorials and practice quizzes on two s complement numbers
CS385 Computer Architecture, Lecture
5
Reading: Patterson & Hennessy - Section B.5.
Topics: ALU
design: full adder, slt operation, HDL design
Lecture slides
Programs:
4-bit-adder.vl, mips-alu.vl, ALU4-mixed.vl
Lecture Notes
- Implementation of a full adder:
- Carry out logic
- Result logic: using 'and', 'or' and inverter and using xor-gate.
- Supporting set on less-than (slt).
- Test for equality (needed for branching)
- Designing the ALU in Verilog
- Carry Lookahead
CS385 Computer Architecture, Lecture
6
Reading: Patterson & Hennessy - Sections 3.3, 3.5.
Topics: ALU design: multiplication, representing floating point
numbers
Lecture slides
Lecture Notes
- Implementing multiplication:
- Using 64-bit adder;
- Using 32-bit adder for the upper 32-bit of the product;
- Avoiding the use of the multiplier register.
- Floating point numbers
- Scientific notation: (-1)^sign * significand * 2^exponent
- Range and precision (overflow and underflow).
- IEEE 754 floating point standard - allows integer comparison:
- normalized representation
- implicit leading 1
- exponent is biased: exponent in [0..0 (most negative), 1..1 (most
positive)]
- bits of the significand represent the fraction between 0 and 1.
- (-1)^S * (1 + s1*2^-1 + s2*2^-2 + ...) * 2^(exponent-bias)
- Problems with floating point arithmetic
Tutorials and
practice quizzes on floating point numbers:
CS385 Computer Architecture, Lecture
7
Reading: Sections 4.1 - 4.3, B.8.
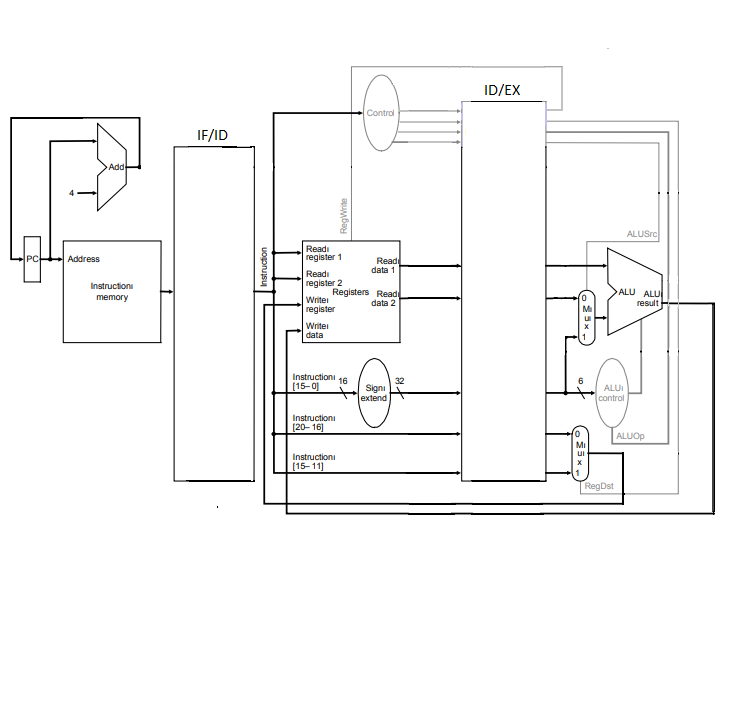
Topics: The Processor,
Building a Datapath
Lecture slides
Programs: mips-regfile.vl, mips-r-type_addi.vl
Lecture Notes
- Abstract level implementation:
- Instruction memory
- Program counter
- Register file
- ALU
- Data memory
- Basic building elements
- Combinational logic
- State elements: D-lathes and D flip-flops
- Clocking methodology: edge triggered
- Fetching instructions and incrementing the program counter
- Register file and execution of R-type instructions
- Datapath for lw and sw instructions (add data memory and sign extend)
- Datapath for branch instructions
Exercises: Run MIPS single cycle animation in Blackboard.
CS385 Computer Architecture, Lecture
8
Reading: Patterson & Hennessy - Section 4.4
Topics: Single-cycle control
Lecture slides
Programs: mips-r-type_addi.vl, mips-simple.vl
Lecture Notes
- ALU control: mapping the opcode and function bits to the ALU control
inputs
- Designing the main control unit
- Operation of the Datapath (single-cycle implementation):
- R-type instructions
- Load (store) word
- Branching instructions
- Problems of the single-cycle implementation
CS385 Computer
Architecture, Lecture 11
Reading: Patterson & Hennessy - B.4,
Section 4.13 (http://booksite.elsevier.com/9780124077263/appendices.php)
Topic: Using Hardware Description Language to Design and Simulate the
MIPS processor
CS385 Computer Architecture, Lecture
13
Reading: Patterson & Hennessy - Section 4.5
Topic:
Introduction to Pipelining
Lecture slides (PDF)
Lecture Notes
- Pipelining by analogy (laundry example):
- Pipelining helps throughput of the entire workload
- Multiple tasks operating simultaneously and using different
resources
- Potential speedup = number of pipe stages
- The pipeline rate is limited by the slowest stage
- Unbalanced lengths of pipe stages reduces the speedup
- The time to "fill" the pipeline and the time "drain" it reduces the
speedup
- Stall for dependencies
- Five stages of the load MIPS instruction
- The pipelined datapath
- Single cycle, multiple cycle vs. pipeline
- Advantages of pipelined execution
- Problems with pipelining (pipeline hazards)
- Structural hazards
- Data hazards
- Control hazards
CS385 Computer Architecture, Lecture
14
Reading: Patterson & Hennessy - Section 4.5, 4.6
Topic: Solving pipeline hazards, Designing a pipelined processor
Lecture
slides I (PDF)
Lecture slides II (PDF)
Lecture Notes
- Structural hazards: single memory
- Control hazards:
- Stall: wait until decision is clear
- Predict: fixed prediction (e.g. fail), dynamic prediction (based on
history)
- Delayed brach (software solution):
add $4, $5,
$6 beq $1,
$2, $40
beq $1, $2, 40
==> add $4, $5, $6
lw $3,
300($0) lw
$3, 300($0)
- Data hazards (dependecies backwards in time):
- Forwarding (bypassing)
- Reordering code
lw $t0,
0($t1)
lw $t0, 0($t1)
lw $t2, 4($t1)
==> lw $t2, 4($t1)
sw $t2,
0($t1)
sw $t0, 4($t1)
sw $t0,
4($t1)
sw $t2, 0($t1)
- Designing a pipelined processor
CS385 Computer Architecture, Lecture
15
Reading: Patterson & Hennessy - Section 4.6, Section 4.13 (http://booksite.elsevier.com/9780124077263/appendices.php)
Topic: Implementing pipeline datapath and control
Lecture slides (PDF)
Lecture Notes
- Splitting datapath into stages: using registers to store parts of the
instruction
- Transferring data forward and backward between the stages: lw example
- Corrected datapath: storing rd for the write back stage.
- Graphically representing pipelines: multiple-clock-cycle vs.
single-clock-cycle diagram
- Pipeline control:
- IF: no control signals to store for later stages (they are always
asserted).
- ID: no control signals to store for later stages (they are always
asserted).
- EX: set RegDst, ALUOp, ALUSrc
- MEM: set Branch, MemRead, MemWrite
- WB: set MemtoReg, RegWrite
- Datapath with control
- Example: running this code through the pipeline in 9
cycles.
lw $10, 20($1)
sub $11, $2,
$3
and $12, $4, $5
or $13, $6,
$7,
add $14, $8, $9
Exercises: Section 4.13
(http://booksite.elsevier.com/9780124077263/appendices.php),
Figures 4.13.11 through 4.13.15.
CS385 Computer Architecture, Lecture
16
Reading: Patterson & Hennessy - Section 4.7, 4.8
Topic:
Implementing data and branch hazard control
Lecture slides (PDF)
Lecture Notes
- Detecting data dependencies
- EX/MEM.Rd = ID/EX.Rs
EX/MEM.Rd = ID/EX.Rt
- MEM/WB.Rd = ID/EX.Rs
MEM/WB.Rd = ID/EX.Rt
- Forwarding
- if (EX/MEM.RegWrite and EX/MEM.Rd = ID/EX.Rs)ForwardA = 10
if (EX/MEM.RegWrite and EX/MEM.Rd = ID/EX.Rt)ForwardB = 10
- if (MEM/WB.RegWrite and MEM/WB.Rd = ID/EX.Rs)ForwardA = 01
if (MEM/WB.RegWrite and MEM/WB.Rd = ID/EX.Rt)ForwardB = 01
- Data hazards and stalls
If (ID/EX.MemRead and
(ID/EX.Rt = IF/ID.Rs or
ID/EX.Rt = IF/ID.Rt))
stall the pipeline
- Branch hazards
- Reducing the delay of branches - move up the address calculation (move
the adder) and the branch decision (add XOR and AND gates)
- Assuming the branch will not be taken
- Flashing instructions in IF, ID, and EX stages, if the branch is
taken
- Advanced pipelining
- Superpipelining
- Superscalar
- Dynamic scheduling
CS385 Computer Architecture, Lecture
17
Reading: Patterson & Hennessy - Chapter 4, Section 4.13 (http://booksite.elsevier.com/9780124077263/appendices.php)
Topics: Review of Datapath, Control and Pipelining, HDL implementation (mips-pipe.vl),
3-stage pipeline (mips-pipe3.vl)
Programs: mips-pipe.vl, mips-pipe3.vl
Lecture
slides (PDF)
Lecture Notes
Datapath
- Abstract level implementation:
- Instruction memory
- Program counter
- Register file
- ALU
- Data memory
- Basic building elements
- Combinational logic
- State elements: D-lathes and D flip-flops
- Clocking methodology: edge triggered
- Basic operations
- Instructions fetch
- Accessing register file and execution of R-type instructions
- Datapath for lw and sw instructions (add data memory and sign
extend)
- Datapath for branch instructions
Control
- ALU control: mapping the opcode and function bits to the ALU control
inputs
- Designing the main control unit
- Operation of the Datapath (single-cycle implementation):
- R-type instructions
- Load (store) word
- Branching instructions
- Problems of the single-cycle implementation
Pipelining
- Basic principles of pipelining
- Pipelining helps throughput of the entire workload
- Multiple tasks operating simultaneously and using different
resources
- Potential speedup = number of pipe stages
- The pipeline rate is limited by the slowest stage
- Unbalanced lengths of pipe stages reduces the speedup
- The time to "fill" the pipeline and the time "drain" it reduces the
speedup
- Stall for dependencies
- MIPS pipelining: the five stages of the lw instruction
- Problems with pipelining:
- Structural hazards
- Data hazards
- Control hazards
- Designing a pipelined processor
- Transferring data forward and backward between the stages
- Pipeline control
- Implementing data and branch hazard control
- Detecting data dependencies
- Forwarding
- Data hazards and stalls
- Branch hazards
- Advanced pipelining
Demo:
CS385 Computer Architecture, Lecture
18
Reading: Patterson & Hennessy - Section 5.1
Topic:
Memory Hierarchy
Lecture slides (PDF)
Lecture Notes
- Memory technologies and trends
- Impact on performance
- The need of hierarchical memory organization
- The principle of locality
- Memory hierarchy terminology
- Basics of RAM implementation
- SRAM: D-latches, three-state buffers, address decoders, two level
addressing
- DRAM: DRAM cell, refreshing
- Error detection and correction
CS385 Computer Architecture, Lecture
19
Reading: Patterson & Hennessy - Sections 5.1-5.3
Topic: The Basics of caches
Lecture slides (PDF)
Programs: cache.vl, cache2.vl
Lecture Notes
- Direct-mapped cache
- Accessing a cache
- Writing to the cache (write-through and write-back schemes)
- Handling cache misses
- Read miss: load the word from memory
- Write miss: write both to the cache and to the memory (using write
buffer)
- Spatial locality caches: keeping consistency on write
- Main memory organization
Exercises: Problems 5.1, 5.2, 5.3, 5.7 from Chapter 5 Exercises in Blackboard
CS385 Computer Architecture, Lecture
20
Reading: Patterson & Hennessy - Section 5.4
Topic:
Improving cache performance
Lecture slides (PDF)
Lecture Notes
- Measuring cache performance
- Stall clock cycles = Instructions * Miss rate * Miss penalty
- Example 1 (reducing CPI):
- 2% - instruction miss; 4% - data miss; 36% - lw/sw; 40 cyc - miss
penalty.
- 2 CPI => CPI_stall = 3.36, i.e. perfect cache is 1.68 times
faster.
- 1 CPI => CPI_stall = 2.36, i.e. perfect cache is 2.36 times
faster.
- Example 2: doubling clock rate => 80 cyc - miss penalty, CPI_stall =
4.75, Performance: 3.36/(4.75/2) = 1.41 faster with stalls, 2 times faster
without stalls.
- Conclusion: cache penalties increase as the machine becomes
faster
- Flexible placement of blocks in the cache
- Direct mapped: Cache index = (Block address) modulo (Cache size); no
search; small tag.
- Set associative: Cache index = (Block address) modulo (Number of sets in
cache); search the set; larger tag.
- Fully associative: Cache index is not determined; search the whole
cache; tag = address.
- Locating a block in the cache: N-way cache requires N comparators and
N-way multiplexor
- Choosing which block to replace: least recently used
- Multilevel caches
Exercises
- Write a sequence of memory references for which:
- the direct mapped cache performs better than the 2-way associative
cache;
- the 2-way associative cache performs better than the fully associative
cache.
- Exercises 5.1, 5.2, 5.3, 5.7 from Chapter 5 Exercises in Blackboard
CS385 Computer Architecture, Lecture
21
Reading: Patterson & Hennessy - Section 5.7
Topic:
Virtual Memory
Lecture slides (PDF)
Lecture Notes
- The need of VM
- Many programs (processes) can use a single memory
- Use a memory exceeding the size of the main memory
- VM organization and terminology: virtual address, physical address, page,
page offset, page fault, memory mapping (translation).
- Design decisions motivated by the very high cost of page faults:
- Large pages (4K-64K)
- Reducing page fault penalties: fully associative VM
- Software management of page faults
- Write-back instead of write-through
- Addressing pages:
- Page table, page table register
- Processes (active, inactive) and page tables
- Page faults
- Replacing pages: LRU, reference (use) bit
- Write-back scheme (dirty bit)
CS385 Computer Architecture, Lecture
22
Reading: Patterson & Hennessy - Section 5.7
Topic:
Virtual Memory optimization
Lecture slides (PDF)
Lecture Notes
- Optimizing address translation - Translation Lookaside Buffer (TLB):
- TLB miss
- Page fault
- TLB associativity
- MIPS R2000 (DECStation 3100) TLB
- Overall operation of a memory hierarchy
- Memory protection with VM
- Using exceptions for handling TLB misses and pages faults: using EPC and
Cause registers
- Summary of VM
CS385 Computer Architecture, Lecture
23
Reading: Patterson & Hennessy - Section 5.8.
Topic: A commmon framework for memory hierarchies
Lecture slides (PDF)
Lecture Notes
- Associativity schemes
- Placing blocks
- Miss rates and cache sizes
- Finding blocks
- Why do we use full associativity and a separate lookup table (page table)
in VM
- Choosing a block to replace
- Writing blocks
- The sources of misses
- The challenge: reducing the miss rate has a negative effect on the overall
performance
- Pentium Pro and PowerPC 604
Exercises (from Chapter 5 Exercises in Blackboard)
- Direct-mapped chaches: 5.2.1, 5.2.2, 5.3
- Associative caches: 5.7.1, 5.7.2, 5.7.3, 5.13.1
- Virtual memory: 5.11.1, 5.11.4, TLB example
CS385 Computer Architecture, Lecture 26
Reading: Chapter 6, Section 2.11
Topic: Multiprocessors
Lecture
slides (PDF)
COD-Chapter7.pdf
Lecture Notes
- Amdahl's Law
- Basic approaches to sharing data and types of connectivity
- Programming multiprocessors
- Multiprocessors connected by a single bus
- A parallel program
- Multiprocessor cache coherency
- Implementing a multiprocessor cache coherency protocol
- Synchronization using coherency, locks, atomic swap
operation
again: addi $t0, $0, 1 # copy locked value
ll $t1, 0($s1)
# load linked
sc $t0, 0($s1) # store conditional
beq
$t0, $0, again # branch if store fails
add $s4, $0, $t1 # put
load value in $s4
CS385 Computer Architecture, Lecture 27
Reading: Chapter 6
Topic: Networks of
muiltiprocessors and clusters
Lecture slides (PDF)
COD-Chapter7.pdf
Lecture Notes
- Shared memory vs. multiple private memories
- Centralized memory vs. distributed memory
- Parallel programming by message passing
- Distributed memory communication
- Memory allocation
- Clusters and network topology
- Modern clusters:
Digital Design Review
Assignment
Log on to Blackboard to see and submit the assignment.
Assignment 1: Assembly Programming in MIPS
(maximum grade 10 points)
Log on to Blackboard to see and submit the
assignment.
Semester Project: Building a mini MIPS
machine (maximum grade 45 points including the presentation)
Log on to Blackboard to see and submit the project.
Midterm Test (20 points)
There will be 20 multiple choice and short answer questions covering the following topics:
- Number systems: binary, two's complement, floating point, conversions between decimal and two's complement and floating point.
- MIPS instruction set architecture and assembly programming
- Instruction format and meaning
- Accessing memory. Note the byte order within the memory word (big-endian, little-endian), see book page A-43
- Single-cycle datapath and control (see http://www.cs.ccsu.edu/~markov/ccsu_courses/385SL8.pdf/slide #5)
- MIPS single-cycle implementation in Verilog HDL (mips-simple.vl)
- Implementing basic CPU components and control
- Implementing and addressing instruction and data memory
- Pipelining
- Number of pipeline stages each instruction takes. Note the particular implementation of the branch to reduce the delay on branching (moving branch decision earlier). See book Section 4.8, Fig. 4.65 (http://www.cs.ccsu.edu/~markov/ccsu_courses/385SL16.pdf/last slide).
- Executing code on the pipelined MIPS (sample questions: How many cycles does this code take?, What is the ALU doing in cycle 9?)
- Identifying data dependencies and hazards in the code
- Resolving hazards by changing code (inserting nops or reordering instrutions)
Final Exam (25 points)
There will be 25 multiple
choice, multiple answer, and short answer questions from the following topics
(see the Review Questions in Blackboard):
- Processor stages and timing
- Pipelining
- Forwarding (checking conditions on pipeline registers)
- Hazard detection and stalling
- Solving branch hazards
- Memory System
- Temporal and spatial locality in programs
- Cache hits and misses
- Cache size
- Virtual memory
- Overall operation of a memory hierarchy
- Direct-mapped chaches: 5.2.1, 5.2.2, 5.3
- Associative caches: 5.7.1, 5.7.2, 5.7.3, 5.13.1
- Virtual memory: 5.11.1, 5.11.4, TLB example
- Multiprocessors
- Amdahl's Law
- Multiprocessor architectures
- Processor Synchronization
- Instruction and data streams
- Parallel programming
{kind=link}